Getting Started with the PyTorch-CUDA12 Chainguard Image
Chainguard offers a minimal, low-CVE image for deep learning with PyTorch that includes the CUDA 12 parallel computing platform for performing computation on NVIDIA GPUs. This introductory guide to Chainguard’s pytorch-cuda12 image will walk you through fine-tuning an image classification model, saving the model, and running it securely for inference. We’ll also compare the security and footprint of the PyTorch-CUDA12 Chainguard Image to the official runtime image distributed by PyTorch and present ways to adapt the resources in this tutorial to your own deep learning projects powered by PyTorch.
Chainguard Images
Chainguard Images are a mix of distroless and development images based on Wolfi. Nightly builds make sure images are up-to-date with the latest package versions and patches from upstream Wolfi.What is Wolfi
Wolfi is a community Linux undistro created specifically for containers. This brings distroless to a new level, including additional features targeted at securing the software supply chain of your application environment: comprehensive SBOMs, signatures, daily updates, and timely CVE fixes.This guide is designed for use in an environment with access to one or more NVIDIA GPUs. However, the code below is written to also run in a CPU-only environment. Please note that tuning the model will take significantly longer in a CPU-only environment.
Testing Access to GPUs
Our first step is to check whether our PyTorch-CUDA environment has access to connected GPUs.
If you don’t already have Docker Engine installed, follow the instructions for installing Docker Engine on your host machine.
Run the below command to pull the image, run it with GPU access, and start a Python interpreter inside the running container.
docker run --rm -it \
--gpus all \
r.dev/chainguard/pytorch-cuda12:latest \
python
Running the above for the first time may take a few minutes to pull the pytorch-cuda12 Chainguard Image, currently 3.3GB. Once the image runs, you will be interacting with a Python interpreter in the running container. Enter the following commands at the prompt to check the availability of your GPU.
Python 3.11.9 (main, Apr 2 2024, 15:40:32) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count()
1
>>> torch.cuda.get_device_name(0)
'Tesla V100-SXM2-16GB'
If the CUDA computing environment is accessible to PyTorch, torch.cuda.is_available() will return True. You should also check that at least one GPU is connected. If your environment only has access to CPU, you can complete the rest of this tutorial, but the step of fine-tuning the pretrained model will take significantly longer.
Once you’ve determined that your environment has access to CUDA and connected GPUs, exit the container by typing Control-d or by typing exit() and pressing Enter. You should be returned to the prompt of your host machine.
Training and Inference Overview
A common workflow in deep learning is to collect labeled data, train a model using that data, and store the model. Later, this model can be loaded and used for inference, or making predictions based on novel inputs not in the training set. For example, we might train a model to recognize animals, then store the model as a serialized and compressed file. Later, and possibly in a new environment, we can load the model and use it to perform a classification task on novel data, such as an image of a whale provided by a user.
It is common for model training to be performed in a development environment, and for inference to be performed in a production environment. We will follow this assumption in this tutorial, but be mindful not to use privileged access or root users in production.
In this tutorial, we’ll fine-tune a pretrained model for an image classification task: classifying whether a provided image is an octopus 🐙, a whale 🐳, or a penguin 🐧. We’ve chosen these animals in appreciation of Wolfi / Chainguard Images, Docker, and Linux, respectively. Rather than train a model from scratch, a process that requires a large set of input data, we’ll start with a ResNet model with 18 layers (resnet18). Using a fine-tuning approach with a pretrained model with relatively few layers is appropriate when using a limited amount of input data. In our case, we’ll be using 60 images for each class, further divided into 40 training and 20 validation images.
For the training step, we’ll be accessing the image as root. This allows us to save the model to a volume and preserve it on the host system. In our inference step, we’ll access the container as the nonroot user, an approach that will be more secure for a production use case.
Fine-Tuning the Model
In this section, we’ll download prepared data to your environment, download a model training script, and run the script to train and save the model. These tasks will all be performed by running the below command. Further details on the Docker command, input data, and script are provided later in the section.
First check that curl and tar are available on your system, and install them if necessary. Docker Engine will also need to be installed.
Run the following to download necessary files and train the model. If there is an issue with the command, see the manual step-by-step instructions below.
Note: if you’re following this tutorial in an environment without access to GPU, remove the --gpus all \ line below before running.
mkdir image_classification && cd image_classification
curl https://codeload.github.com/chainguard-dev/pytorch-cuda-getting-started/tar.gz/main | \
tar -xz --strip=1 pytorch-cuda-getting-started-main/ && \
docker run --user root --rm -it \
--gpus all \
-v "$PWD/:/home/nonroot/octopus-detector" \
cgr.dev/chainguard/pytorch-cuda12:latest \
-c "python /home/nonroot/octopus-detector/image_classification.py"
In the current version of the image, you may see the following message: UserWarning: Attempt to open cnn_infer failed: handle=0 error during model training. This is only a warning and can safely be ignored.
The above command creates a new folder, image_classification, and changes the working directory to that folder. It then uses curl to download the training script and training and validation images from GitHub as a tar file and extracts the files. A container based on the pytorch-cuda12 image is then created and the script and data are shared between host and container in a volume. The model is trained using the provided script and data, and the resulting model is saved to the volume.
Training should take 1-3 minutes in a GPU-equipped environment, and 20-30 minutes in a CPU-only environment. Once the command completes, you can check your current working directory for a trained model as a .pt file:
$ ls
README.md image_classification.py
data octopus_whale_penguin_model.pt
Manual Steps to Fine-Tune the Model
Below are manual steps to perform the above download and training procedure interactively. You may wish to follow these steps if you need to modify the above for your own use case, if you’d like to better understand the steps involved, or if you have difficulty running the above command in your environment. These steps use git clone rather than curl.
In the below steps, the prompt of your host machine will be denoted as (host) $, while the prompt of the container machine will be denoted as (container) $
Check that you have Git and Docker installed:
(host) $ git --version git version 2.30.2 (host) $ docker --version Docker version 20.10.17, build 100c701Clone the repository with the training and validation data and the training script and
cdinto the cloned repository:(host) $ git clone https://github.com/chainguard-dev/pytorch-cuda-getting-started.git (host) $ cd pytorch-cuda-getting-startedRun the below command to start an interactive session in a running pytorch-cuda12 Chainguard Image with root access. If your environment doesn’t have access to GPU, remove the
--gpus all \line before running. Note the volume option, which creates a volume on the container based on the current working directory, allowing access to our training script and data inside the container. Remember that this guide assumes you are training the model in a controlled development environment—do not use root access in any production senario.(host) $ docker run --user root --rm -it \ --gpus all \ -v "$PWD/:/home/nonroot/octopus-detector" \ cgr.dev/chainguard/pytorch-cuda12:latestYou should now have access to an interactive shell inside the container. Navigate to the created volume:
(container) $ cd /home/nonroot/octopus-detector/ (container) $ pwd /home/nonroot/octopus-detectorRun the model-training script:
(container) $ python image_classification.py Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth 100.0% 🐙 Epoch 0/24 🐳 train Loss: 0.9276 Acc: 0.5583 🐧 val Loss: 0.2275 Acc: 0.9500 [...] 🐙 Epoch 24/24 🐳 train Loss: 0.1940 Acc: 0.9167 🐧 val Loss: 0.0248 Acc: 1.0000 Training complete in 1m 39s Best val Acc: 1.000000If the script ran successfully, you should have a saved model serialized as a
.ptfile in the current working directory:(container) $ ls octopus_whale_penguin_model.pt data image_classification.pyAt this point, you’ve trained your model. Shut down the container by pressing
Control-dor by typingexitand pressingEnter. Since we used a volume, the model should also be present on the host machine:(host) $ ls octopus_whale_penguin_model.pt image_classification.py data
Running Inference
You have now downloaded the resnet18 pretrained model and fine-tuned it to detect three classes of images: octopuses, whales, and penguins. Now that the model is trained, we can load it, pass in a new image, and receive the model’s prediction. Using an existing model for prediction is called inference, and in many common scenarios inference is run in a production environment. For this reason, we’ll access our existing model with the nonroot user in this section.
The script (image_classification.py) run in the above commands has been written to check if a model exists in the same folder and, if present, load it. It will also perform inference if a path to an image is passed as an argument when the script is run. Since we should now have a model file present on our host machine, let’s go ahead and run inference on a new image of an octopus.
Feel free to find your own image of an octopus on the web, or run the below command to download an image not in the training data. The training data used realistic images, so you may not wish to choose, for example, a stylized or cartoon image of an octopus.
{kind=link}
curl https://raw.githubusercontent.com/chainguard-dev/pytorch-cuda-getting-started/main/inference-images/octopus.jpg > octopus.jpg
Now that we have a novel input, let’s run inference to classify the image:
docker run --rm -it \
--gpus all \
-v "$PWD/:/home/nonroot/octopus-detector" \
cgr.dev/chainguard/pytorch-cuda12:latest \
-c "python /home/nonroot/octopus-detector/image_classification.py /home/nonroot/octopus-detector/octopus.jpg"
After running this, you should see the model’s classification of the image as output:
octopus
Feel free to try the above inference on other images of octopuses, whales, and penguins. The model should have high accuracy for images similar to those in the training set, which consists of photorealistic images.
Advantages of Chainguard Images for Production ML
Chainguard Images are built with security in mind, from the ground up. They include fewer packages, a lighter footprint, SBOMs, and undergo active and ongoing CVE remediation. Let’s compare the pytorch/pytorch:2.2.2-cuda12.1-cudnn8-runtime provided by PyTorch with the pytorch-cuda12 Chainguard Image using Docker Scout.
Official PyTorch Runtime Image
$ docker scout cves pytorch/pytorch:2.2.2-cuda12.1-cudnn8-runtime
:package: Image Reference pytorch/pytorch:2.2.2-cuda12.1-cudnn8-runtime
| digest | sha256:3a352be3ede6b499065c8fc0fe5a1122875ac1d619af113ddf902d788c1ba8d2 |
| vulnerabilities |     |
| size | 4.1 GB |
| packages | 268 |
Now let’s compare with the pytorch-cuda12 Chainguard Image:
PyTorch-CUDA12 Chainguard Image
$ docker scout cves cgr.dev/chainguard/pytorch-cuda12:latest
:package: Image Reference cgr.dev/chainguard/pytorch-cuda12:latest
| digest | sha256:8ec67ed18d1a0404af74dd1e2621ea6d4aace2903be9b7a7c8671ef0a11b1996 |
| vulnerabilities |   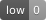 |
| size | 3.3 GB |
| packages | 33 |
As of April 18, 2024, the pytorch-cuda12:latest image has no CVEs recognized by Docker Scout. Further, the Chainguard Image has 33 packages compared to 268 in the image provided by PyTorch. That’s 235 fewer packages to worry about remediating in the future.
Many packages included by default in the official PyTorch image, such as the dash package for dashboard creation or the pillow package for image manipulation, are needed for some projects but not others. If you decide you need additional packages for your project, you can install them with the pip package manager.
Notes on the Script
In this section, we’ll review the script provided in the above steps, highlighting some common options and approaches and a few ways the script might be adapted to other use cases. Deep learning is a complex and emerging field, so this section can only provide a high-level overview and a few recommendations for moving forward.
To fine-tune a model for image classification as we did here, you can replace the provided training and validation data with your own. The script examines the number of folders in the training set to determine the targeted number of classes. The folder names are used as class labels. We used 40 training and 20 validation images for each class, but a ratio of 5:1 training to validation may also produce good results.
By fine-tuning a pretrained model, we took advantage of transfer learning, meaning that the pretrained model (resnet18) was already trained on inputs with relevance to our classification task. Because we used transfer learning, the relatively small amount of input data was still sufficient for good accuracy in our fine-tuned model. If you’re working with a large amount of input data, you might consider using a larger pretrained model, such as resnet34. In addition, if training using significantly more data or training using limited computation relative to the task, you may consider the more efficient convolutional neural network as fixed feature extractor approach, which trains only one attached layer rather than updates the original model.
PyTorch maintains a set of guides that are frequently updated. These provide a good starting point when undertaking a new project in PyTorch. If you’re new to the field of deep learning, the book Deep Learning for Coders with Fastai and PyTorch hosts freely available materials on GitHub.